1.Scrapy简介
scrapy是一个基于Twisted的异步处理框架,是纯python实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性极强。可以灵活的完成各种需求。我们只要定制开发几个模块就可以轻松的实现一个爬虫!
scrapy的架构介绍:
engine:引擎,处理整个系统的数据流处理,触发事务、是整个框架的核心。
item:项目,它定义了爬取结果的数据结构,爬取的数据结构会被赋值成Item对象
Scheduler:调度器,接受引擎发过来的请求并将其加入队列当中,在引擎再次请求的时候将请求提 供给引擎
Downloader:下载器, 下载网页内容返回给蜘蛛(spiders)。
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需 要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
1.Scrapy基本命令
scrapy genspider xxx baidu.com (xxx不能和项目名称相同,后跟网址是 爬虫的目标网址)
scrapy startproject xxx
开始一个爬虫项目
scrapy list
查看当前存在的爬虫文件
scrapy crawl xxx
执行目标爬虫文件
scrapy crawl xxx -o data.json
执行目标爬虫文件并将结果保存在 data.json 文件中
csv文件相同,只需要将后缀名改为 .csv
scrapy view http://www.4399.com
查看页面源码在浏览器中的样子
如 4399网页
scrapy bench
检测 scrapy模块是否安装成功
scrapy 支持 css选择器和 xpath 抽取器 和 selector
scrapy也支持 css 和 xpath 的联合使用,如
先进入 交互模式 scrapy shell http://xxxxxx
response.css('/img').xpath('@src').extract()
获取 img 标签中的 src属性 一般为图片
看一下scrapy框架的基本结构
这里项目名称为 myspider
2.项目实战
目标:爬取西刺代理IP
获取 id,端口号,地址,是否匿名,协议类型,存活时间,最后一次检测时间
并将结果保存在 csv 文件中
开始工作了
首先这是我的项目结构图
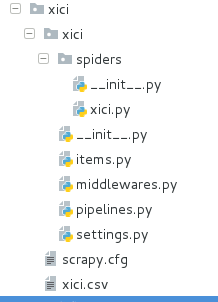
项目名称为 xici
(1)为了防止 403禁止 所以我在 settings配置文件中加入 user-agent,伪装谷歌浏览器
并设置不遵守目标网站的 robots 协议

(2)虽然伪装浏览器成功了,但网站还有可能通过访问频率来判断是否为爬虫软件,所以我设置了爬取延迟为2秒

以西刺网站为例,如果不设置延迟的话,会出现 503 服务器拒绝客户端请求,并在一段时间内不允许任何爬取操作
当然设置代理 IP 池并随机获取 ip 更为保险
(3)上代码
首先在 Items.py文件中定义一个类,即要爬取的数据属性

接下来在创建的 spiders目录中创建一个 xici.py文件,用来写入具体爬取操作
import scrapy
from xici.items import XiciItem 导入定义的类
class BasicSpider(scrapy.Spider):
name = 'xici'
start_urls = ('https://www.xicidaili.com') 规定爬取目标首页
def start_requests(self):
reqs=[]
for i in range(1,10): 规定爬取十页内容,当然也可以设置更多
req=scrapy.Request('https://www.xicidaili.com/nn/%s' %(i))
reqs.append(req)
return reqs 此函数用来循环爬取每一页内容
def parse(self, response): 解析函数
ip_list=response.xpath('//table[@id="ip_list"]')
trs=ip_list[0].xpath('tr')
items=[]
for ip in trs[1:]:
item=XiciItem()
item['ip']=ip.xpath('td[2]/text()')[0].extract()
item['port']=ip.xpath('td[3]/text()')[0].extract()
item['address']=ip.xpath('td[4]/a/text()').extract()
item['niming']=ip.xpath('td[5]/text()').extract()
item['type']=ip.xpath('td[6]/text()').extract()
item['time']=ip.xpath('td[9]/text()')[0].extract()
item['checktime']=ip.xpath('td[10]/text()')[0].extract()
items.append(item)
return items
解析用了 xpath抽取技术,这里不再细讲
进入项目目录并将数据写入 csv 文件
cd xici
scrapy crawl xici -o xici.csv
效果图

当然也可以写入到 json 文件中,但因为 json 默认采用Ascii编码,所以要设置编码格式
在 settings 文件中添加
FEED_EXPORT_ENCODING='utf-8'
如果不配置,就会出现中文乱码,出现的是 unicode 编码
最终效果图

这只是 scrapy 框架中最简单的爬虫项目
3.保存在 Mysql 数据库中
在 pipelines 文件中定义一个新类
代码如下
import pymysql
from scrapy.utils.project import get_project_settings
写入数据库
class MysqlPipeline(object):
def connect_db(self):
从settings文件中导入数据库连接
settings=get_project_settings()
self.host=settings['MYSQL_HOST']
self.name=settings['MYSQL_DBNAME']
self.user=settings['MYSQL_USER']
self.password=settings['MYSQL_PASSWORD']
self.charset=settings['MYSQL_CHARSET']
self.port=settings['MYSQL_PORT']
连接数据库
self.conn=pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name, 数据库名
charset=self.charset,
)
操作数据库对象
self.cursor=self.conn.cursor()
连接数据库
def open_spider(self,spider):
self.connect_db()
关闭数据库连接
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
写入数据库
def process_item(self,item,spider):
写入数据库内容,根据要求设置要写入的字段
sql='insert into xici(ip,port,address,niming,type,time,checktime)
values("%s","%s","%s","%s","%s","%s","%s")'
%(item['ip'],item['port'],item['address'],item['niming'],item['type'],item['time'],
item['checktime'])
执行sql语句
self.cursor.execute(sql)
需要强制提交数据
self.conn.commit()
return item
在 settings 中配置
ITEM_PIPELINES ={ 'xici.pipelines.MysqlPipeline':200,} 同步定义的管道类名
MYSQL_HOST='127.0.0.1' 本地地址
MYSQL_DBNAME='xici' 数据库名称
MYSQL_USER='root' 数据库用户名
MYSQL_PASSWORD='westos' 数据库密码
MYSQL_PORT=3306 数据库端口号
MYSQL_CHARSET='utf8' 数据库编码格式
完成这一切后,在命令行执行
scrapy crawl xici
接着进入数据库查看数据


这里我爬取了10页内容,即900条数据,并保存在数据库中
这些只是 scrapy 框架中一个简单的项目
后面会接触到更深的爬虫